Começando por esse post vamos simular ocorre quando temos a exaustão dos pools de memória do Kernel do Windows.
Essa exaustão pode ocorrer devido ao memory leak (ou vazamento de memória), que é quando uma aplicação tem um bug em seu código e em condições de corrida falha em “devolver” ao sistema a memória alocada (comando free da linguagem C por exemplo). Ou ainda, quando a carga de trabalho é maior do que o servidor pode suportar (o que é agravado pelos modificadores “/PAE”, “/3GB” no arquivo “boot.ini”, uso do AWE, múltiplas interfaces de rede, entre outras coisas) nesse último caso, mesmo sem falhas nas aplicações ou serviços a máquina sofre dos efeitos da exaustão de recursos.
Para fins de simulação foi propositalmente causando um leak no paged pool usando a ferramenta “NotMyFault” da SysInternals.
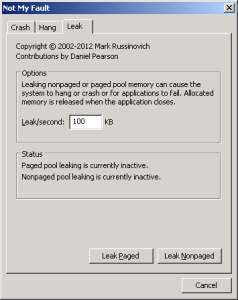
Ao mesmo tempo em que essa aplicação está “esvaziando” o pool, podemos ver aumentando o total alocado pela sua tag (Leak) através da ferramenta PoolMon:
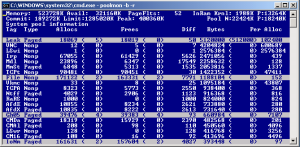
Por falar nisso, começando com o Windows 2003, é possível “rastrear” as alocações nos pool através das tags que são esses quatro caracteres que servem para identificar qual é o driver é responsável pela alocação. As alocações nos pools de memoria são diferentes daqueles feitas pelas aplicações, uma aplicação tem seu próprio espaço de memória ou VAS (Virtual Address Space), ao passo que, no Kernel Mode, frações do mesmo espaço são divididas por vários programas, o Kernel mantém uma estrutura de controle dessas alocações.
Sobre a função que os driver utilizam para alocar memória e as regras para fazê-lo:
https://msdn.microsoft.com/en-us/library/windows/hardware/ff544520(v=vs.85).aspx
Uma listagem relacionando drivers e tags pode ser encontrada no link abaixo:
http://blogs.technet.com/b/yongrhee/archive/2009/06/24/pool-tag-list.aspx
Se temos um situação de exaustão do pool (consideramos que o pool está ficando baixo quando restarem menos de 50MB) e temos a predominância do consumo relativa a um tag. No exemplo da imagem acima nota-se que é a tag “Leak”. Podemos (1) pesquisar uma tabela de tags, ou (2) usar o seguinte comando:

No Windows os drivers ficam em “c:\Windows\System32\drivers”.
Encontrado o driver que é responsável pelo “vazamento”, uma atualização desse driver deverá resolver o problema. Isso vale tanto para driver do Windows como para driver de dispositivos. Uma falha relativamente comum de ocorrer é a descrita no seguinte KB:
https://support.microsoft.com/en-us/kb/940307
Algumas tags porém, não são exatamente drivers, e nesse caso o “tratamento” poderá ser uma pouco mais complicado.
Abaixo enumerei exemplos e possíveis causas:
|
MmSt |
Se isso ocorre é um servidor de arquivos é imprescindível verificar se temos arquivos “.pst” sendo servidor pela rede. http://blogs.technet.com/b/askperf/archive/2011/09/23/getting-to-know-the-mmst-pool-tag.aspx http://blogs.technet.com/b/askperf/archive/2007/01/21/network-stored-pst-files-don-t-do-it.aspx |
|
Toke |
Essa é a memória utilizada para armazenas os Tokens de segurança do Windows, portanto se temos “pressão” em memória causada por essa tag precisamos investigar a origem das autenticações, para isso é aconselhável utilizar o ProcessExplorer e olhar as handles do processo “lsass.exe”, verificando qual(is) contas e qual(is) aplicações, application pools do IIS, tarefa agenda, etc. é a origem do problema. |
|
CM31 |
Essa tag tem que ver com o registro do Windows, um registro fragmentado ou demasiado grande (registry bloat) é a razão por trás do consumo excessivo de pool por essa tag. |
Então, após ler esse post, se ao monitorar o “nível” dos pools (como vimos no post anterior) você encontrar o sistema próximo da exaustão, já vai ser possível identificar se temos um leak em algum driver do sistema ou de dispositivo, ou ainda, se a carga de trabalho está “pesada” demais para esse servidor. Num próximo post, vou tratar com um pouco mais detalhe a identificação de um memory leaks (já que isso é útil também em servidores X64).
Use a sessão de comentários se precisa esclarecer alguma dúvida ou quiser deixar sua opinião sobre esse post.































